Desabafos e aprendizados sobre o evento de falha de segurança na iugu no dia 7 de abril
… e não um vazamento de dados da iugu
Ontem foi um dia interessante na minha vida, foi meu aniversário, porém ganhei um presente que não esperava, um incidente que acabou tomando proporções rapidamente pela maneira que foi compartilhada.
Antes de mais nada somos todos humanos e erramos, por isto em uma empresa costumamos ter políticas, procedimentos e segregação de funções para mitigar riscos.
Longe de mim isentar qualquer culpa sobre a falha de segurança, porém conseguimos ter a agilidade suficiente para resolver antes de qualquer estrago.
Sim, seus dados estão seguros conosco e não houve vazamento. Se você é nosso cliente, não é preciso se preocupar com senhas e chaves de API, nem com dados de pagamento gerenciados por nós.
Este é o relato curto. Agora vamos aos detalhes / post-mortem.
Obs: Tentarei explicar de uma forma que tanto usuários mais leigos quanto mais técnicos entendam.
Aqui na iugu, nós estamos sempre tentando melhorar, aprender mais a cada dia, aplicar boas práticas que vemos por aí de infraestrutura, de segurança e de negócios.
Hoje, boa parte de nossa infra fica na AWS (Amazon Web Services), nosso provedor de nuvem. Há cerca de dois anos, decidimos seguir novas boas práticas de mercado e migrar de uma estrutura de uma única conta para uma estrutura de múltiplas contas, com uma segregação ainda maior de responsabilidades, parte do nosso movimento de implementar políticas e procedimentos cada vez mais maduros para garantir a segurança e continuidade do negócio.
Estratégia de Multi Contas em Nuvem:

Como vocês devem imaginar, levar uma fintech que já não é pequena para uma estrutura dessas é um trabalho que dura mais de um ano, cheio de complexidades e restruturações, e tudo isso com o mínimo de downtime possível.
Correndo o risco de super simplificar a infra para melhor entendimento, nossa tech stack é basicamente composta da seguinte forma:

Explicando rapidamente nossa aplicação, nossos dados são armazenados em dois blocos: blocos de dados e blocos de dados sensíveis. Como a base de dados é muito grande, temos um serviço que funciona como um índice para encontrar rapidamente informações nos serviços de dados.
O serviço onde houve a exposição foi o de busca, especificamente em uma configuração errada na nova versão do serviço que estávamos criando, e que ainda não estava em produção. Usamos a solução ElasticSearch aqui para isto, que é como se fosse um ‘mini Google’, particular para os nossos dados. Este serviço, não salva todas as informações disponíveis nos serviços de dados, apenas as mais buscadas. Além disto, jamais armazenamos informações de dados sensíveis (Chaves de API, Dados de Cartão, etc), neste tipo de serviço.
Nesta semana, estávamos caminhando para a fase final dessa migração e tivemos uma configuração errada neste componente de serviço de busca, no novo e não no antigo.
No dia 7 de abril pela manhã, começamos a migração do serviço de buscas (Elastic). Para isto, foi criado um novo grupo de servidores (cluster) na nova conta de AWS de destino, por volta das 08:04, este serviço continha zero dados de busca até aquele momento.
Logo em seguida, aproximadamente às 08:07, começamos uma sincronização (cópia), de todos os dados de busca do serviço antigo na conta anterior, para este novo serviço, na conta nova. A cada minuto a partir daí, dados de busca da conta antiga eram copiados para a nova conta.
Por volta das 11:00, esse serviço foi desligado porque a estratégia em questão para migração foi ineficiente e demoraria semanas. A partir deste momento, não havia mais qualquer possibilidade de acesso a este serviço.
As 16:09, recebemos um contato de um profissional de segurança, que enviou um relatório de falha de segurança. A empresa dele, monitorava sites como Shodan (que é um Google para segurança). Aparentemente o Shodan havia indexado (salvo) informações sobre o nosso novo serviço de busca:
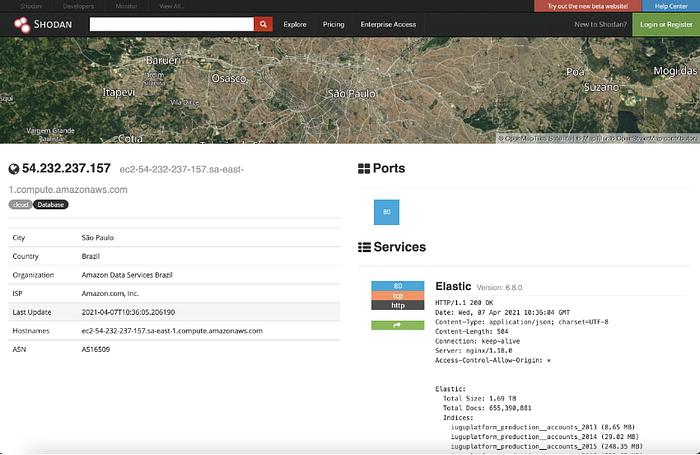
Em seguida a esta descoberta, começamos a averiguar a situação e repassar a informação internamente para mais detalhes. Entre o dia 7 e a manhã do dia 8, o consultor de segurança, antes de nosso primeiro contato, publicou no Twitter o ocorrido. Naquele momento, o problema já havia sido solucionado.
Em paralelo, começamos um trabalho com toda a diretoria da iugu, e com squads alocadas exclusivamente para averiguar o tamanho da exposição, além de assessorias de imprensa, DPOs e relacionados a LGDP.
Em um primeiro momento foi bem tenso, porque o primeiro sentimento é de você ter sido exposto a algo muito maior. Alocamos gente para analisar os logs do novo serviço de busca e identificamos um único acesso externo a dados (Fora o acesso do Shodan de listagem de índices), entre as 9 e 11 horas.
Constatamos que este acesso fez samples de 10 mil registros em cada índice do serviço de busca, lembrando que muitos destes índices ainda estavam zerados ou com informações parciais:

Ao mesmo tempo, tínhamos o contato do consultor de segurança que relatou o problema, para ter certeza que foi o único com acesso aos dados de busca.
Após uma conversa com o consultor, confirmamos que ele não havia feito cópia destes dados parciais (10 mil registros de alguns índices).
Em paralelo, este tweet começou a tomar corpo e começamos a ter clientes e jornalistas questionando antes mesmo que pudéssemos analisar todos os dados. Além disto, tínhamos uma preocupação grande com o órgão regulador (Bacen) e com a Agência Nacional de Proteção de Dados (ANPD). Eu tento ser acessível ao máximo e ativo em grupos de CEOs (por conta de toda minha trajetória como CEO e fundador da iugu) e em grupos de tecnologia, e muita, muita gente veio conversar comigo perguntando sobre o que aconteceu e os detalhes.
Mesmo com tudo que estava acontecendo ao mesmo tempo, dei um jeito de responder cada pessoa ou grupo e fui posicionando em tempo real sobre os detalhes. Mas isto só não foi o suficiente, a grande maioria dos CEOs e CTOs que me conhecem entenderam o que estava acontecendo e com base na transparência que sempre prezei, ficaram satisfeitos com o contexto geral e iriam aguardar o post-mortem do acontecido.
O problema começou aí, muita gente começou a disseminar informação errada em grupos, coisas como “iugu vazou todos os dados, saia o mais rápido, pegue seus dados, etc” e alguns veículos chegaram a publicar que foi um vazamento de 1.7TB de informações. Isto foi o suficiente para transformar meu celular e minhas redes em um caos total. Uma exposição dos dados de busca (não explorada), sem informações de login, senha ou dados de pagamento se tornou um negócio muito maior do que deveria ser, e a brecha sequer havia sido utilizada para baixar os dados disponíveis de forma a ser vendida na internet posteriormente (Deepweb e afins).
Passei a noite acordado pensando no ocorrido. Acredito que lidamos bem com a situação como um todo. Só que a Internet não perdoa, cheguei a ver absurdos no Twitter como “Manda o profissional ou a equipe embora” e coisas drásticas, como se as pessoas tivessem virado robôs e não estivessem mais sucetíveis a erro. Na minha visão, para crescer você vai errar às vezes, o importante é mitigar os riscos e seguir em frente melhorando. E tomar cuidado para que um único erro não seja grande o suficiente para matar o seu negócio ou o seu projeto.
Eu sei que fizemos tudo que estava a nosso alcance e tenho certeza que nossos profissionais trabalharam da melhor forma possível. Tivemos aprendizados, e vamos aplicar para sermos melhores a cada dia. E o mais importante de tudo, durante a janela de exposição dos dados, não houve download dos dados por terceiros.
Voa iugu!
Postmortem
Sumário:
Configuração errada em um novo serviço de busca de dados parcialmente sincronizado em 7 de Abril de 2021
Linha do tempo dos eventos:
7 de Abril, 08:04 — Criação de um novo serviço de buscas (Elastic) em uma nova conta AWS
7 de Abril, 08:07 — Início da sincronização/cópia dos dados do serviço na conta antiga
7 de Abril, ~11:00 — Serviço desligado por conta da ineficiência da migração
7 de Abril, 16:09 — Notificação de exposição de dados pelo consultor de segurança
7 de Abril, 16:23 — Encaminhamento da informação para pessoal da Iugu
8 de Abril, 10:20 — Tweet público do consultor sobre a brecha, já corrigida
8 de Abril, dia todo — Análise de logs, de segurança, de dados.
8 de Abril, dia todo — Trabalho em conjunto com nossas assessorias de imprensa, de incidentes e relacionados. Além do trabalho com nossas diretorias e equipes de tecnologia e segurança.
8 de Abril, meio do dia — Tweets e publicações de artigos já contando a história sem esperar nossa análise.
8 de Abril, fim do dia — Constatação que não houve download das informações do serviços de busca nem acesso a dados dos serviços de dados ou dados sensíveis como credenciais e cartões.
8 de Abril, fim do dia — Publicação do nosso posicionamento e do que havia acontecido.
8 de Abril, fim do dia — Alterações pequenas em publicações já existentes com nosso posicionamento, sem deixar claro que não houve download de dados.
Falha humana ou sistêmica:
Humana
Impacto:
Acesso público ao serviço de buscas parcialmente sincronizado.
Confiança na marca iugu.
Causa Raiz:
Configuração equivocada de um novo serviço de busca (ElasticSearch)
Solução:
Correção da configuração equivocada que permitia acesso aos dados de busca.
Implementação de procedimento de migração de dados na política de segurança.
Implementação de procedimento de configuração de serviços de nuvem na política de segurança.
Contratação de ferramenta para monitoramento de serviços como Shodan e afins.
